WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback









 Shan Xia
Shan Xia

 Xiaofeng Xu
Xiaofeng Xu


Abstract
As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, misalignment with real-world user preferences, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages in-situ user feedback during conversations with LLMs to create preference datasets automatically. Given a corpus of multi-turn user-LLM conversation, WildFeedback identifies and classifies user feedback to LLM responses between conversation turns. The user feedback is then used to create examples of preferred and dispreferred responses according to users’ preference. Our experiments demonstrate that LLMs fine-tuned on WildFeedback dataset exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed checklist-guided evaluation. By incorporating in-situ feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users.
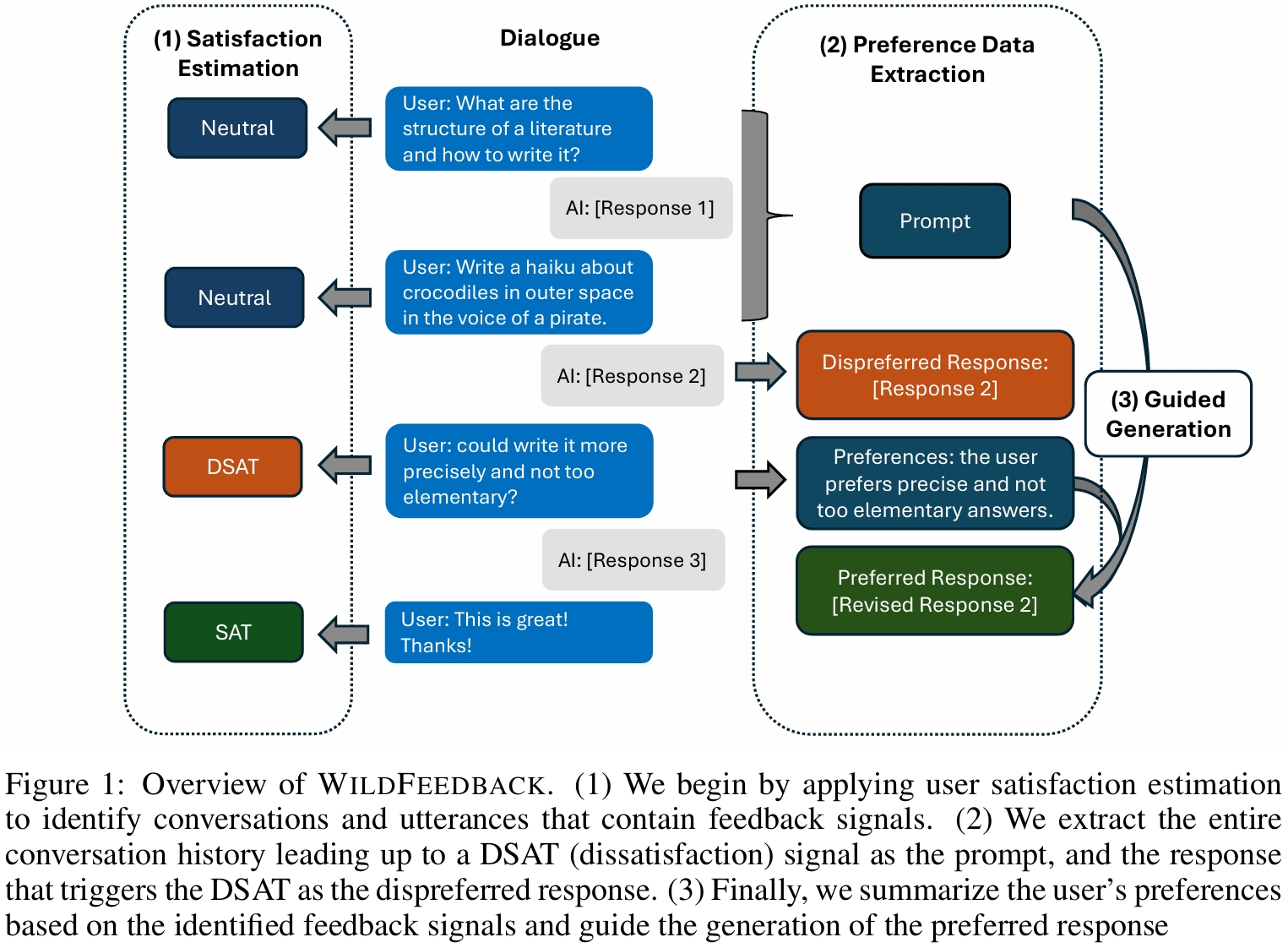
Method Overview
WildFeedback operates through a three-step process:
Feedback Signal Identification
This step involves analyzing user-LLM interactions to identify feedback signals (satisfaction or dissatisfaction). Feedback signals are extracted from real dialogues using rubrics to classify user satisfaction (SAT) and dissatisfaction (DSAT).
Preference Data Construction
Conversations containing satisfaction (SAT) or dissatisfaction (DSAT) signals are used to identify prompts and summarize user preferences, such as preferences for more detailed or precise responses. Dispreferred responses are directly taken from instances that triggered DSAT signals, while preferred responses are generated using GPT-4 or on-policy models guided by the summarized user preferences. To ensure safety, additional instructions prevent generating harmful content, and moderation filters are applied. This approach produces a dataset that better captures authentic user preferences, enhancing LLM alignment with real-world user expectations.
User-guided Evaluation
The user-guided evaluation in WildFeedback aligns model assessments with real user preferences by incorporating direct user feedback into the evaluation process. Instead of relying solely on automated or human annotator judgments, this method uses feedback signals from user-LLM interactions to guide evaluations, ensuring they reflect actual user expectations. Evaluators, including LLMs like GPT-4, are provided with a checklist of summarized user preferences from the dataset, which informs their assessment of model responses. This approach reduces biases common in traditional benchmarks and ensures that the evaluation process accurately measures how well models meet user needs, leading to more reliable and user-aligned performance metrics.
Key Takeaways
We applied WildFeedback to the WildChat dataset and constructed a preference dataset of more than 20k samples. To validate the effectiveness of WildFeedback, We finetune Mistral, Phi 3, LLaMA 3 on it and compare their performances with the non-finetuned models on MT-Bench, AlpacaEval 2, Arena-Hard, and the held-out test set of WildFeedback. For WildFeedback evaluation, we report the win, tie, lose percentage against the off-the-shelf instruct models with GPT-4 as the judge. Results are shown in Table 3. Some key takeaways are
- Training models on the WildFeedback dataset can significantly and consistently boost model performance across all benchmarks. Models trained the dataset exhibit higher win rates across AlpacaEval 2, Arena-Hard, and MT-Bench, as well as improved performance in both settings of WildFeedback (with and without a checklist).
- WildFeedback significantly enhances model alignment with in-situ user feedback. As detailed in the previous section, WildFeedback has two versions, differing in whether the preferred responses are generated by GPT-4 or the policy models themselves. Compared to off-the-shelf instruction models, those trained on either version of WildFeedback demonstrate a stronger alignment with real user preferences, winning much more often on the WildFeedback test set as compared with the off-the-shelf instruct models and the models trained on UltraFeedback.
- WildFeedback does not compromise model performance on other benchmarks. Training on either version of WildFeedback not only aligns models more closely with user preferences but also does not compromise performance on other benchmarks; in most cases, it even leads to improvements.

BibTeX
@misc{shi2025wildfeedbackaligningllmsinsitu,
title={WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback},
author={Taiwei Shi and Zhuoer Wang and Longqi Yang and Ying-Chun Lin and Zexue He and Mengting Wan and Pei Zhou and Sujay Jauhar and Sihao Chen and Shan Xia and Hongfei Zhang and Jieyu Zhao and Xiaofeng Xu and Xia Song and Jennifer Neville},
year={2025},
eprint={2408.15549},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.15549},
}