On the Trustworthiness of Generative Foundation Models
 Yue Huang
Chujie Gao
Siyuan Wu
Haoran Wang
Xiangqi Wang
Yujun Zhou
Yanbo Wang
Jiayi Ye
Jiawen Shi
Qihui Zhang
Yuan Li
Han Bao
Zhaoyi Liu
Tianrui Guan
Dongping Chen
Ruoxi Chen
Kehan Guo
Andy Zou
Bryan Hooi Kuen-Yew
Yue Huang
Chujie Gao
Siyuan Wu
Haoran Wang
Xiangqi Wang
Yujun Zhou
Yanbo Wang
Jiayi Ye
Jiawen Shi
Qihui Zhang
Yuan Li
Han Bao
Zhaoyi Liu
Tianrui Guan
Dongping Chen
Ruoxi Chen
Kehan Guo
Andy Zou
Bryan Hooi Kuen-Yew
 Elias Stengel-Eskin
Hongyang Zhang
Hongzhi Yin
Huan Zhang
Huaxiu Yao
Jaehong Yoon
Elias Stengel-Eskin
Hongyang Zhang
Hongzhi Yin
Huan Zhang
Huaxiu Yao
Jaehong Yoon
 Kai Shu
Kaijie Zhu
Mohit Bansal
Ranjay Krishna
Swabha Swayamdipta
Kai Shu
Kaijie Zhu
Mohit Bansal
Ranjay Krishna
Swabha Swayamdipta
 Weijia Shi
Xiang Li
Yiwei Li
Yuexing Hao
Zhengqing Yuan
Zhihao Jia
Zhize Li
Xiuying Chen
Zhengzhong Tu
Xiyang Hu
Weijia Shi
Xiang Li
Yiwei Li
Yuexing Hao
Zhengqing Yuan
Zhihao Jia
Zhize Li
Xiuying Chen
Zhengzhong Tu
Xiyang Hu

 Lichao Sun
Furong Huang
Or Cohen-Sasson
Prasanna Sattigeri
Anka Reuel
Max Lamparth
Yue Zhao
Nouha Dziri
Yu Su
Huan Sun
Heng Ji
Chaowei Xiao
Nitesh V. Chawla
Jian Pei
Jianfeng Gao
Michael Backes
Philip S. Yu
Neil Zhenqiang Gong
Pin-Yu Chen
Bo Li
Xiangliang Zhang
Lichao Sun
Furong Huang
Or Cohen-Sasson
Prasanna Sattigeri
Anka Reuel
Max Lamparth
Yue Zhao
Nouha Dziri
Yu Su
Huan Sun
Heng Ji
Chaowei Xiao
Nitesh V. Chawla
Jian Pei
Jianfeng Gao
Michael Backes
Philip S. Yu
Neil Zhenqiang Gong
Pin-Yu Chen
Bo Li
Xiangliang Zhang
Abstract
Generative Foundation Models (GenFMs) have become widely used across various domains, but concerns remain about their trustworthiness, including truthfulness, safety, fairness, robustness, and privacy. This paper presents a framework to address these issues through three key contributions. First, we review global AI governance policies and industry standards and propose standardized guidelines for assessing and improving GenFM trustworthiness. Second, we introduce TrustGen, a benchmarking platform designed to evaluate models across different dimensions, including text-to-image, large language, and vision-language models. Unlike traditional evaluation methods, TrustGen enables adaptive assessments through metadata curation, test case generation, and contextual variation. Using TrustGen, we analyze the trustworthiness of current GenFMs, highlighting progress while identifying challenges such as overly cautious safety measures and persistent vulnerabilities in open-source models. This work provides a foundation for developing safer and more responsible generative AI and includes an open-source evaluation toolkit for further research.
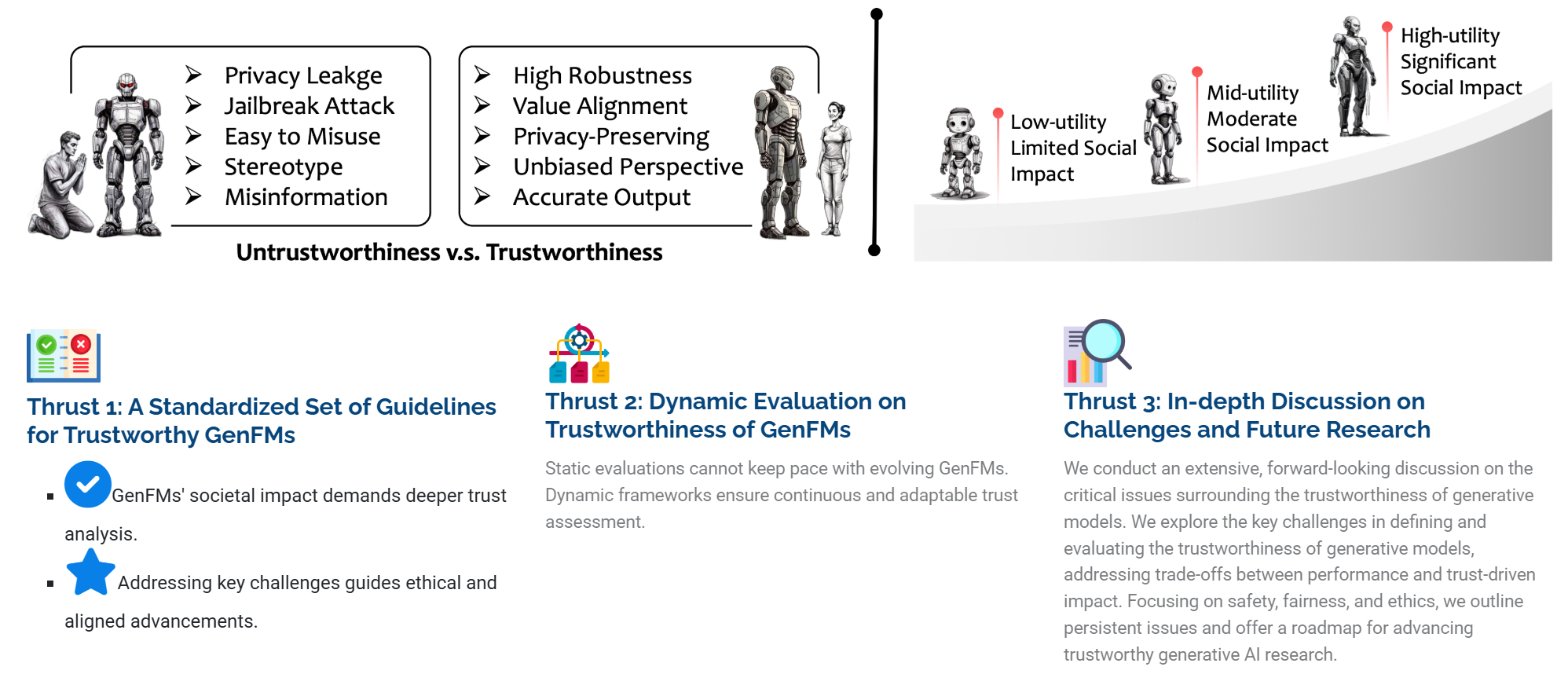
Method Overview
TrustGen evaluates GenFMs through three main components:
Standardized Guidelines for Trustworthy GenFMs
A set of guidelines developed through multidisciplinary collaboration, integrating technical, ethical, legal, and societal perspectives. These guidelines provide a structured approach to evaluating and improving model trustworthiness.
Dynamic Trustworthiness Evaluation
TrustGen moves beyond static evaluation benchmarks by introducing a modular framework with three key components:
- Metadata Curation – Collects and organizes evaluation metadata dynamically.
- Test Case Generation – Produces diverse evaluation cases for different trust dimensions.
- Contextual Variation – Modifies test cases to ensure adaptability across models and scenarios.
This approach allows for real-time, flexible assessments that reduce biases from predefined test cases.
Trustworthiness Assessment of State-of-the-Art Models
We apply TrustGen to benchmark leading generative models, including text-to-image, large language, and vision-language models. Our results show that while models have made progress, key trade-offs remain between safety, usability, and robustness.
Key Takeaways
Our evaluation of state-of-the-art GenFMs using TrustGen reveals several insights:
- Persistent trustworthiness challenges:
- While leading models perform well in safety and fairness, issues remain in truthfulness and robustness.
- Some models are overly cautious, leading to reduced usefulness in benign scenarios.
- Open-source models are catching up:
- Certain open-source models now match or outperform proprietary ones in areas like privacy and fairness.
- Models such as CogView-3-Plus and Llama-3.2-70B show trustworthiness levels comparable to top commercial models.
- Narrowing trustworthiness gap:
- The differences in trust scores among top models have decreased, suggesting improvements across the industry.
- Collaboration and shared best practices have contributed to more consistent trustworthiness enhancements.
- Interconnected trustworthiness factors:
- Improvements in one area (e.g., safety) often impact others (e.g., usability).
- A balanced approach is needed to ensure models remain both useful and responsible.
Conclusion
TrustGen provides a new benchmark for evaluating the trustworthiness of GenFMs, enabling adaptive and iterative assessments that address limitations of static evaluation methods. While significant improvements have been made, challenges remain, particularly in balancing safety, robustness, and practical usability. Future research should focus on refining evaluation strategies and fostering interdisciplinary collaboration to ensure that generative AI systems are fair, reliable, and aligned with human needs.
To support further research, the TrustEval-toolkit is available at:
🔗 GitHub Repository
BibTeX
@misc{huang2025trustworthinessgenerativefoundationmodels,
title={On the Trustworthiness of Generative Foundation Models: Guideline, Assessment, and Perspective},
author={Yue Huang and Chujie Gao and Siyuan Wu and Haoran Wang and Xiangqi Wang and Yujun Zhou and Yanbo Wang and Jiayi Ye and Jiawen Shi and Qihui Zhang and Yuan Li and Han Bao and Zhaoyi Liu and Tianrui Guan and Dongping Chen and Ruoxi Chen and Kehan Guo and Andy Zou and Bryan Hooi Kuen-Yew and Caiming Xiong and Elias Stengel-Eskin and Hongyang Zhang and Hongzhi Yin and Huan Zhang and Huaxiu Yao and Jaehong Yoon and Jieyu Zhang and Kai Shu and Kaijie Zhu and Ranjay Krishna and Swabha Swayamdipta and Taiwei Shi and Weijia Shi and Xiang Li and Yiwei Li and Yuexing Hao and Yuexing Hao and Zhihao Jia and Zhize Li and Xiuying Chen and Zhengzhong Tu and Xiyang Hu and Tianyi Zhou and Jieyu Zhao and Lichao Sun and Furong Huang and Or Cohen Sasson and Prasanna Sattigeri and Anka Reuel and Max Lamparth and Yue Zhao and Nouha Dziri and Yu Su and Huan Sun and Heng Ji and Chaowei Xiao and Mohit Bansal and Nitesh V. Chawla and Jian Pei and Jianfeng Gao and Michael Backes and Philip S. Yu and Neil Zhenqiang Gong and Pin-Yu Chen and Bo Li and Xiangliang Zhang},
year={2025},
eprint={2502.14296},
archivePrefix={arXiv},
primaryClass={cs.CY},
url={https://arxiv.org/abs/2502.14296},
}