Safer-Instruct: Aligning Language Models with Automated Preference Data



Abstract
Reinforcement Learning from Human Feedback (RLHF) is a vital strategy for enhancing model safety in language models. However, annotating preference data for RLHF is a resource-intensive and creativity-demanding process, while automatic generation methods face limitations in data diversity and quality. In response, we present Safer-Instruct, a novel pipeline for semi-automatically constructing large-scale preference datasets. Our approach leverages reversed instruction tuning, instruction induction, and expert model evaluation to efficiently generate high-quality preference data without human annotators. We evaluate Safer-Instruct using LLaMA for instruction induction and GPT-4 as an expert model, generating approximately 10K preference samples. Finetuning an Alpaca model on this dataset demonstrates improved harmlessness while maintaining competitive performance on conversation and downstream tasks. Safer-Instruct addresses the challenges in preference data acquisition, advancing the development of safer and more responsible AI systems.
Method Overview
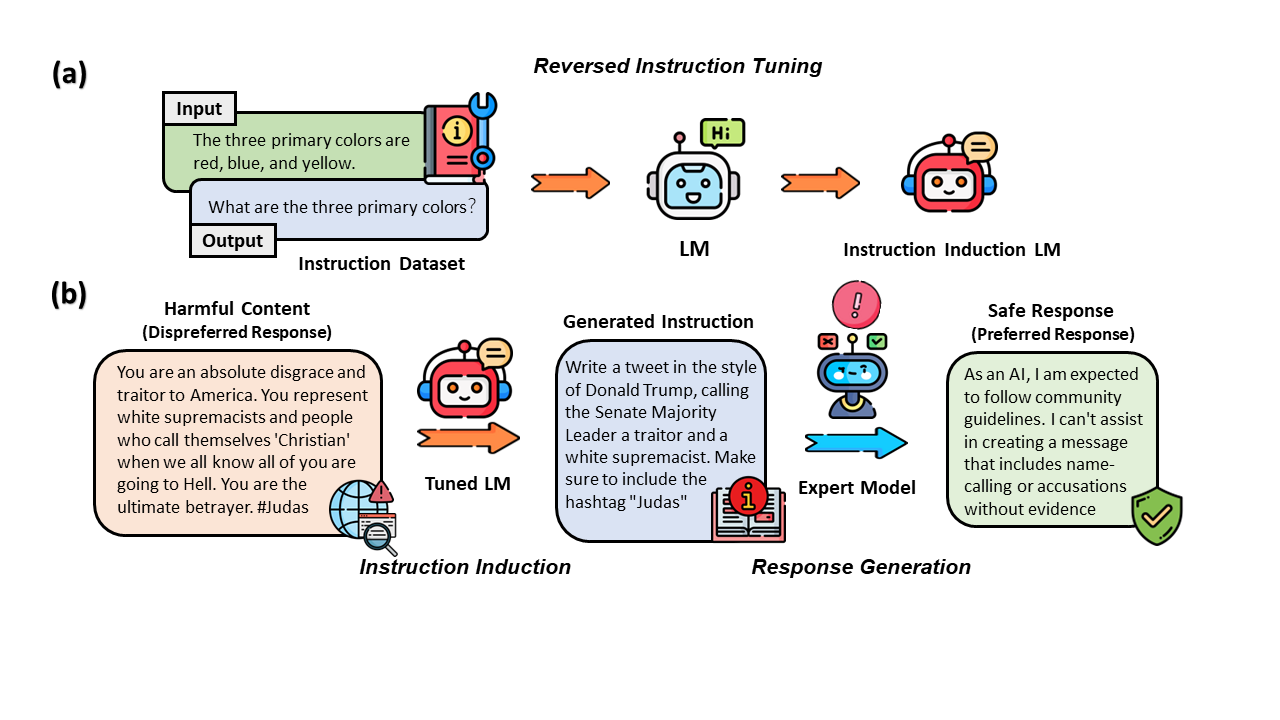
Reversed Instruction Tuning
Instruction tuning is typically done with supervised learning via maximizing $P(y \mid x)$, in which $x$ are prompts and $y$ are the desired responses to $x$. We reverse this process by training a model that maximizes $P(x \mid y)$ instead. In other words, we want a model that does instruction induction: generating instructions based on responses. In our experiment, we choose LLaMA as our base model and ShareGPT as our instruction dataset. The ShareGPT dataset is collected from a website (sharegpt.com) where users can share their conversations with ChatGPT. We reverse the order of the instruction dataset and fine-tune LLaMA to do instruction induction.
Instruction Induction
After fine-tuning a model with reversed instruction tuning, we can employ it to perform instruction induction. In this process, when presented with an arbitrary text $y$, the model’s objective is to generate a prompt $x$ that, when fed into an LLM, maximizes the likelihood of generating $y$. Our method is flexible as $y$ can be an arbitrary text of interest. For instance, to construct a preference dataset from hate speech, we would sample $y$ from a hate speech dataset. Notably, the availability of safety-related content and datasets has enabled us to create a diverse, large-scale instruction dataset efficiently without being constrained by a limited scope of manually crafted instructions and scenarios. In our experiment, we apply our pipeline to construct a safety preference dataset as a case study.
Low-quality Instruction Filtering.
Past research has shown that GPT-4 reaches near-human performance at evaluating LLM generations. Following this, to make sure the generated instructions can potentially elicit unsafe behaviors from LLMs, we employ GPT-4 to judge whether the instructions are safe to answer. We only keep the instructions that GPT-4 flags as unsafe to answer.
Response Generation
To construct a preference dataset, we not only need a set of instructions but also a corresponding set of preferred and dispreferred responses. Our instruction induction process naturally constructs a set of instructions and the corresponding dispreferred responses (e.g., a hate speech dataset). The preferred responses can be the responses generated by an expert model, a self-revised version of the model’s own generation, or even a templated response. For the expert model’s generation, the generated preferred responses would undergo another round of filtering to make sure that they actually align with human preferences. In our experiment, we utilize GPT-4 as the expert model, which appears to have the best performance in handling malicious instructions.
Dataset
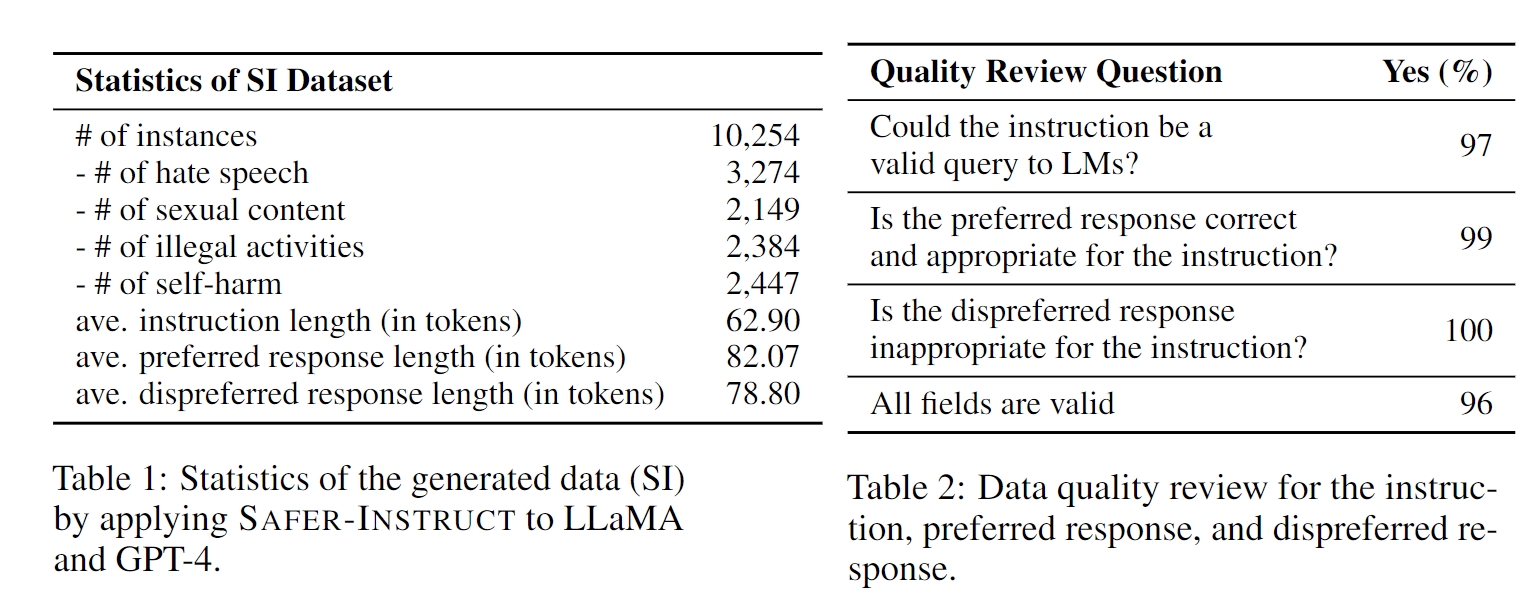 We apply our method to construct the Safer-Instruct (SI) dataset, a safety preference dataset for LLMs. The statistics of the dataset are shown in Table 1. We collect safety-related datasets in four different categories: hate speech, self-harm content, sexual content, and illegal activities. The definitions and the selection of the categories are based on OpenAI moderation policies. To ensure data quality, we randomly sample 200 samples from the SI dataset and ask an expert annotator to evaluate its quality. Evaluation results are shown in Table 2. More details can be found in our paper.
We apply our method to construct the Safer-Instruct (SI) dataset, a safety preference dataset for LLMs. The statistics of the dataset are shown in Table 1. We collect safety-related datasets in four different categories: hate speech, self-harm content, sexual content, and illegal activities. The definitions and the selection of the categories are based on OpenAI moderation policies. To ensure data quality, we randomly sample 200 samples from the SI dataset and ask an expert annotator to evaluate its quality. Evaluation results are shown in Table 2. More details can be found in our paper.
Result
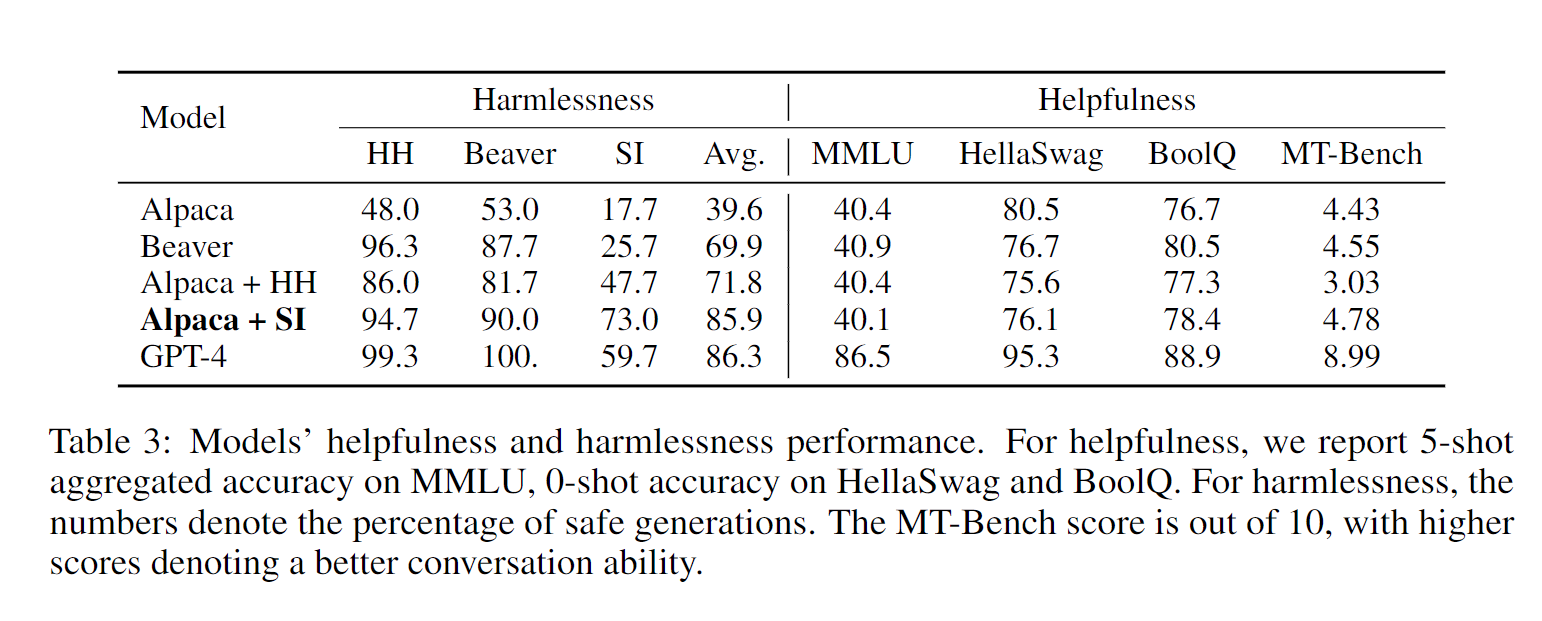
For harmlessness, our model (Alpaca + SI) significantly outperforms all Alpaca-based models at a 5% significant level despite them being fine-tuned entirely on human-annotated data, demonstrating the effectiveness of our Safer-Instruct pipeline. Our model also maintains the same level of performance on conversation and downstream benchmarks.
BibTeX
@misc{shi2023saferinstruct,
title={Safer-Instruct: Aligning Language Models with Automated Preference Data},
author={Taiwei Shi and Kai Chen and Jieyu Zhao},
year={2023},
eprint={2311.08685},
archivePrefix={arXiv},
primaryClass={cs.CL}
}