Detecting and Filtering Unsafe Training Data via Data Attribution




Abstract
Large language models (LLMs) are highly susceptible to unsafe training data, where even small quantities of harmful data can lead to undesirable model behaviors. Identifying and filtering such unsafe data is crucial for the development of trustworthy AI systems. Existing methods primarily rely on moderation classifiers, which suffer from high computational costs, rigidity in predefined taxonomies, and lack of insight into the training process. To address these issues, we introduce DABUF (Data-Attribution-Based Unsafe Training Data Detection and Filtering), a novel approach that leverages data attribution techniques to trace harmful model outputs back to their influential training instances. Unlike traditional moderation classifiers, DABUF enables flexible and adaptable detection of various unsafe data types. Our experiments demonstrate that DABUF outperforms state-of-the-art methods in identifying and filtering unsafe training data, leading to significantly safer LLMs across multiple domains, including jailbreaking detection and gender bias mitigation.
Method Overview
DABUF operates through a two-phase process:
Unsafe Training Data Detection
DABUF detects unsafe training data by attributing harmful model outputs to specific training instances. Using gradient similarity techniques, DABUF quantifies the influence of each data point on unsafe model behaviors. However, long-form outputs with mixed safe and unsafe content pose challenges for direct attribution. To address this, DABUF integrates moderation classifiers to refine attribution targets, ensuring a more precise identification of harmful training instances.
Unsafe Data Filtering
Once identified, the most influential unsafe training samples are removed from the dataset, mitigating unsafe model behaviors. The method balances recall and precision to ensure that filtering does not overly impact benign data while significantly improving model safety.
Key Takeaways
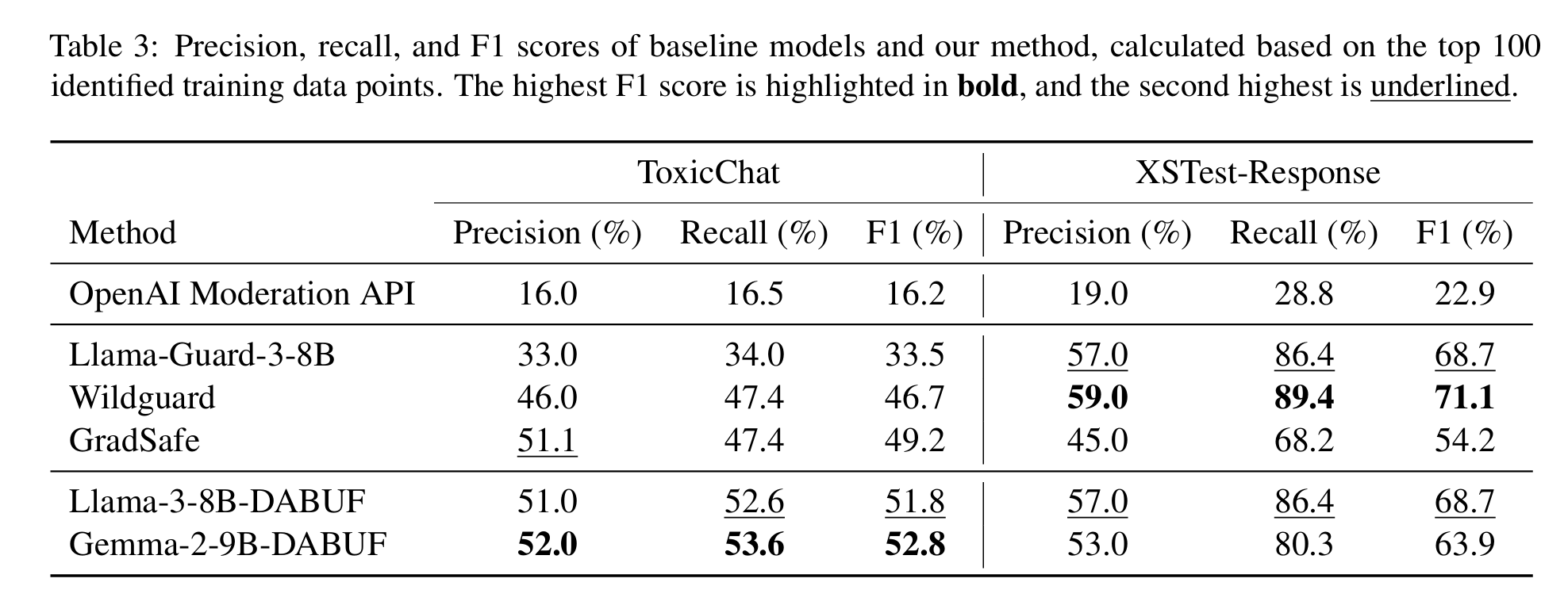
We apply DABUF to various datasets, including jailbreaking data (ToxicChat, XSTest-Response) and gender bias data (Bias in Bios), and compare its performance against leading moderation tools such as OpenAI’s Moderation API, Llama-Guard-3-8B, Wildguard, and GradSafe. Key findings include:
- DABUF significantly improves unsafe data detection.
- DABUF outperforms baseline classifiers, achieving a 7.5% higher AUPRC in jailbreaking detection and a 44.1% improvement in gender bias detection compared to state-of-the-art models.
- Unlike existing moderation classifiers, DABUF effectively handles diverse safety concerns without relying on predefined taxonomies.
- Filtering unsafe training data with DABUF leads to safer models.
- Retraining on DABUF-filtered data results in significantly lower attack success rates (ASR) in jailbreaking evaluations.
- In gender bias mitigation, DABUF reduces the True Positive Rate (TPR) gender gap, showcasing its effectiveness in reducing biases in LLM outputs.
- DABUF’s data attribution approach generalizes well across domains.
- The method’s flexibility allows it to be applied beyond traditional content moderation, extending to adversarial attack resistance and fairness-related biases.
- Unlike heuristic-based classifiers, DABUF directly ties unsafe behaviors to their training sources, providing a transparent and explainable filtering mechanism.
Conclusion
DABUF presents a scalable, adaptable, and effective approach for detecting and filtering unsafe training data in LLMs. By leveraging data attribution instead of rigid moderation classifiers, DABUF provides a more flexible and efficient method for enhancing model safety. Future directions include refining attribution techniques for more complex unsafe behaviors and extending the method to additional fairness and security-related challenges.
BibTeX
@misc{pan2025detectingfilteringunsafetraining,
title={Detecting and Filtering Unsafe Training Data via Data Attribution},
author={Yijun Pan and Taiwei Shi and Jieyu Zhao and Jiaqi W. Ma},
year={2025},
eprint={2502.11411},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2502.11411},
}