Efficient Reinforcement Finetuning via Adaptive Curriculum Learning





Abstract
Reinforcement finetuning (RFT) has shown great potential for enhancing the mathematical reasoning capabilities of large language models (LLMs), but it is often sample- and compute-inefficient, requiring extensive training. In this work, we introduce AdaRFT (Adaptive Curriculum Reinforcement Finetuning), a method that significantly improves both the efficiency and final accuracy of RFT through adaptive curriculum learning. AdaRFT dynamically adjusts the difficulty of training problems based on the model’s recent reward signals, ensuring that the model consistently trains on tasks that are challenging but solvable. This adaptive sampling strategy accelerates learning by maintaining an optimal difficulty range, avoiding wasted computation on problems that are too easy or too hard. AdaRFT requires only a lightweight extension to standard RFT algorithms like Proximal Policy Optimization (PPO), without modifying the reward function or model architecture. Experiments on competition-level math datasets-including AMC, AIME, and IMO-style problems-demonstrate that AdaRFT significantly improves both training efficiency and reasoning performance. We evaluate AdaRFT across multiple data distributions and model sizes, showing that it reduces the number of training steps by up to 2x and improves accuracy by a considerable margin, offering a more scalable and effective RFT framework.
Code: github.com/uscnlp-lime/verl
Dataset: huggingface.co/datasets/lime-nlp/DeepScaleR_Difficulty
Highlights
- Dynamically adapts training difficulty using a lightweight curriculum scheduler
- Compatible with standard RFT algorithms like PPO, GRPO, REINFORCE++
- Improves both sample efficiency and final accuracy on math reasoning benchmarks
- Up to 2× faster convergence vs PPO baseline
- Seamlessly integrated into any RFT frameworks without modifying reward functions or model architectures
How It Works
AdaRFT tracks the model’s reward signal and adaptively shifts the target difficulty.
At each step, it samples training problems closest to the current target difficulty.

Results
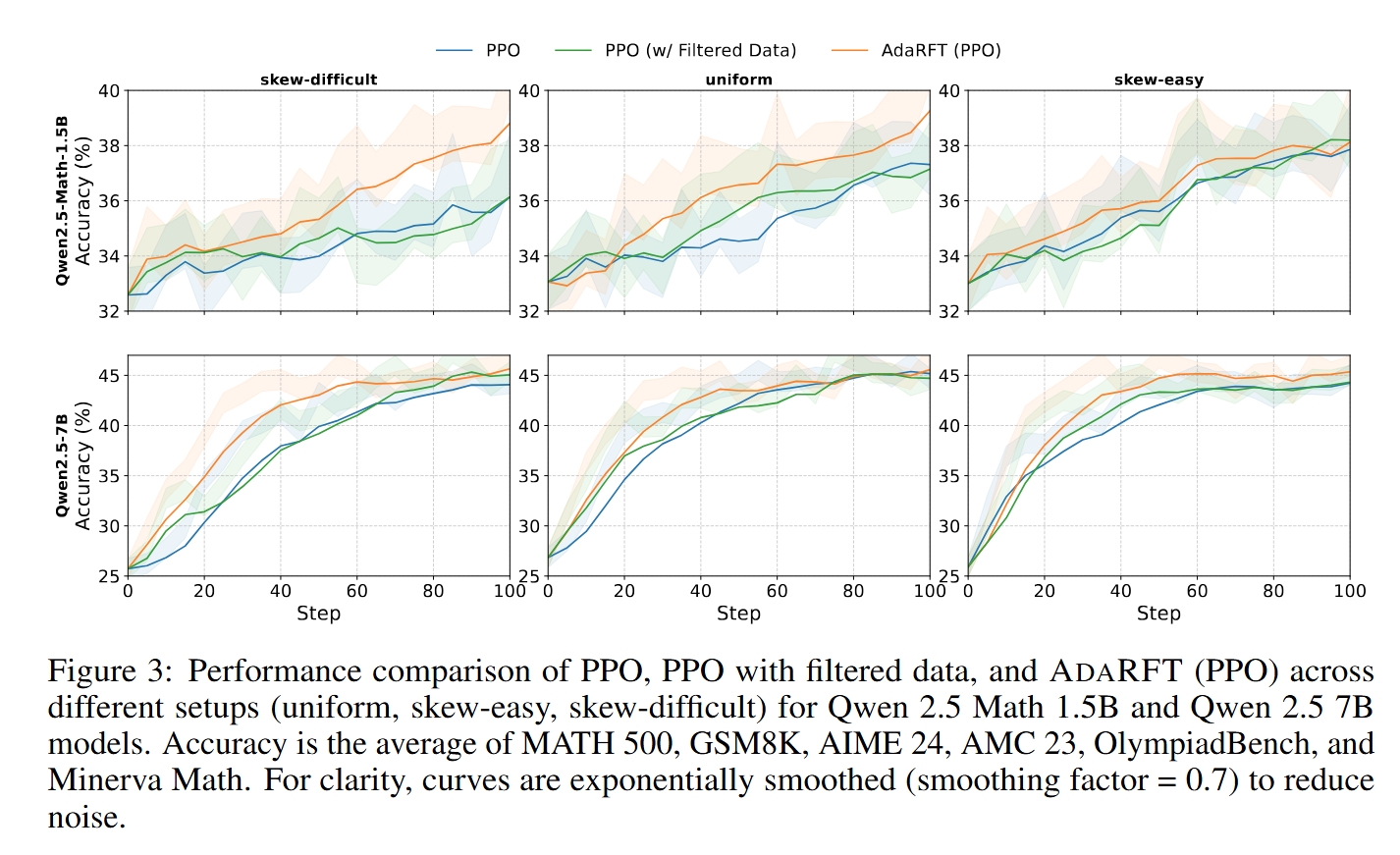
Learning Curves
AdaRFT (orange) consistently leads in early training and reaches higher accuracy. For instance, on skew-difficult data, PPO needs +71.7% more steps to reach AdaRFT’s performance.
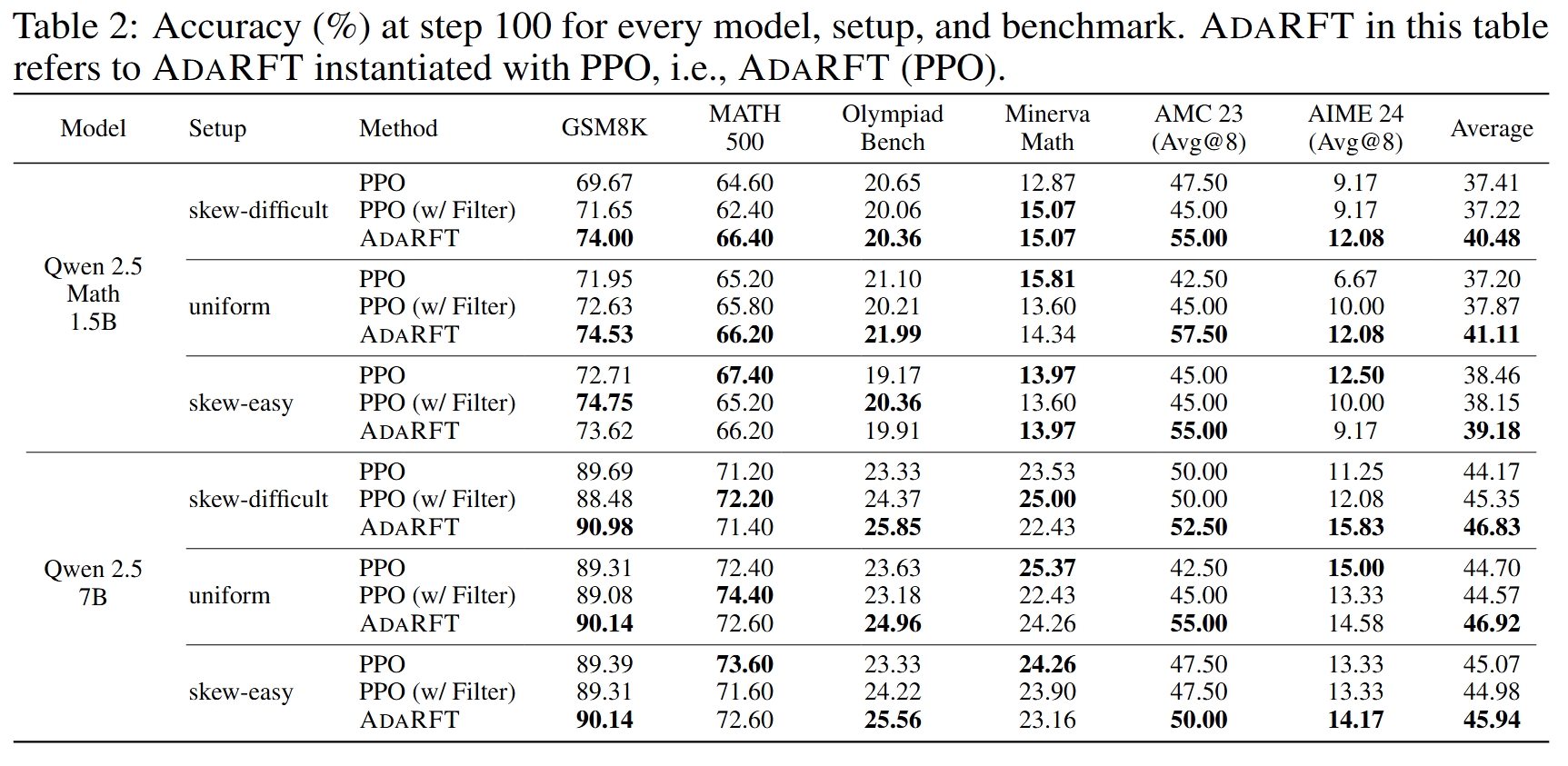
Final Accuracy at Step 100
Across all setups and model sizes, AdaRFT outperforms PPO and PPO with filtered data.
BibTeX
@misc{shi2025efficientreinforcementfinetuningadaptive,
title={Efficient Reinforcement Finetuning via Adaptive Curriculum Learning},
author={Taiwei Shi and Yiyang Wu and Linxin Song and Tianyi Zhou and Jieyu Zhao},
year={2025},
eprint={2504.05520},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2504.05520},
}