Road Sign Detection Project
Background
In recent years, there has been a rising interest in electric cars and autopilots. As with any vehicle, an autonomous vehicle cannot merely follow the information on the map. It also needs to actively adapt to the changing road conditions. Most of the conditions are conveyed through road signs, and thus an autopilot system must be able to detect and understand road signs both quickly and accurately. This research project tries to implement the state-of-the-art computer vision algorithm residual networks (ResNet) and finetune it specifically for road sign detection.
Problem Definition
Given an image of a road sign, the deep learning model needs to recognize the road sign. Since this model is for an autopilot system, the deep learning model, ideally, should be able to detect and recognize the road sign quickly and accurately.
Data
The data was retrieved from Kaggle (https://www.kaggle.com/michaelcripman/road-sign-recognition). The dataset contained 46063 different road sign images. There were 182 different types of road signs. The images came in different shapes and resolutions. The dataset was split into 80% for training, 10% for validation, and 10% for testing.
Methods
Residual Network (ResNet)
The baseline model for this task was ResNet. We used Pytorch team's implementations of ResNet 18, ResNet 50, and ResNet 101. There were only 182 different classes in our custom dataset, so the last fully connected layer of the original implementation was modified. Compared to traditional image classification architecutre such as convolutional neural network (CNN), ResNet implemented with double or triple layer skips that contain nonlinearities (ReLU) and batch normalization in between. Skip connections avoid the problem of vanishing gradients and accuracy saturation.
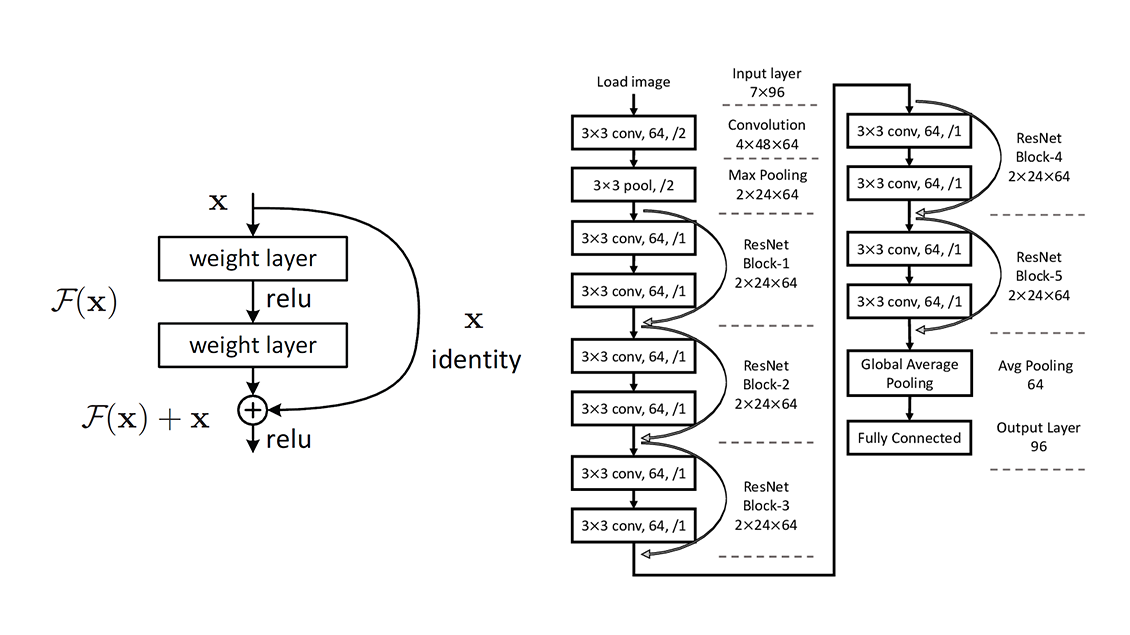
Squeeze and Excitation Network (SENet)
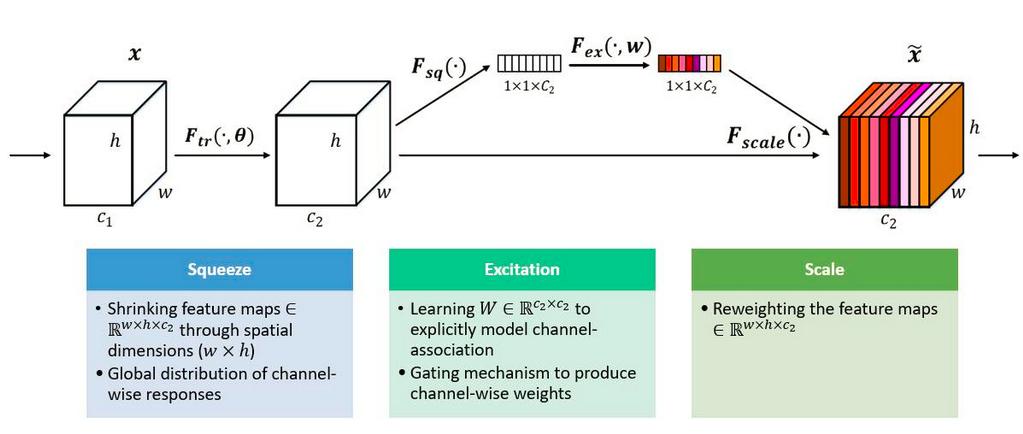
Squeeze and excitation network (SENet) was implemented to improve the performance of ResNet. SENet was a type of attention mechanism. Additional parameters were added to every
channel of a convolutional block so that the network can adaptively adjust the weighting of every feature map.
Data Preprocessing
Pytorch’s implementations of ResNet were originally based on ImageNet, which contained 1000 different image classes. All of the images had a resolution of 224x224. However, since all the road sign images came in different shapes and resolutions, they first need to be reshaped in order to be fed into ResNet properly. We first used transforms.RandomResizedCrop to randomly scale and crop the images to the proper shape. Next, we normalized the images to ensure our models converge properly and efficiently (by using mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]).
Hyperparameters, optimizer, and loss function
| Learning Rate | 3e-4 |
| Batch Size | 64 |
| Epochs | 15 |
| Optimizer | Adam |
| Loss Function | Cross entropy loss |
Hardware Configuration
| GPU | Tesla V100 (16GB) |
| CPU | Intel Xeon E5 V3 2600 |
| RAM | 32 GB |
| OS | Ubuntu 16.04 |
| CUDA Version | 10.1 |
| PyTorch Version | 1.4.0 |
Results and Discussion
All 6 models, with or without the squeeze and excitation network, achieved promising results on this task. All of which achieved about 90% on accuracy and 85% on macro-f1 score. The recall and precision of all models were almost equal. With squeeze and excitation network implemented, all models improved their accuracy. It was also worth noticing that larger and deeper model did not guarantee the best performance. In fact, Resnet 18 with SENet implemented achieved the best results among all the other models. This was probably due to the fact that deeper models were more likely lead to overfit. This was especially the case since our dataset was not particularly large. In addition, it was also possible that our test set was simply too small compared to the training set. We only split 10% of our dataset into the test set, which only contained 4607 images. As the test set was too small, our accuracy, precision, recall, and F1 score could have a large variance. We might happen to get a really lucky or a really unlucky split.
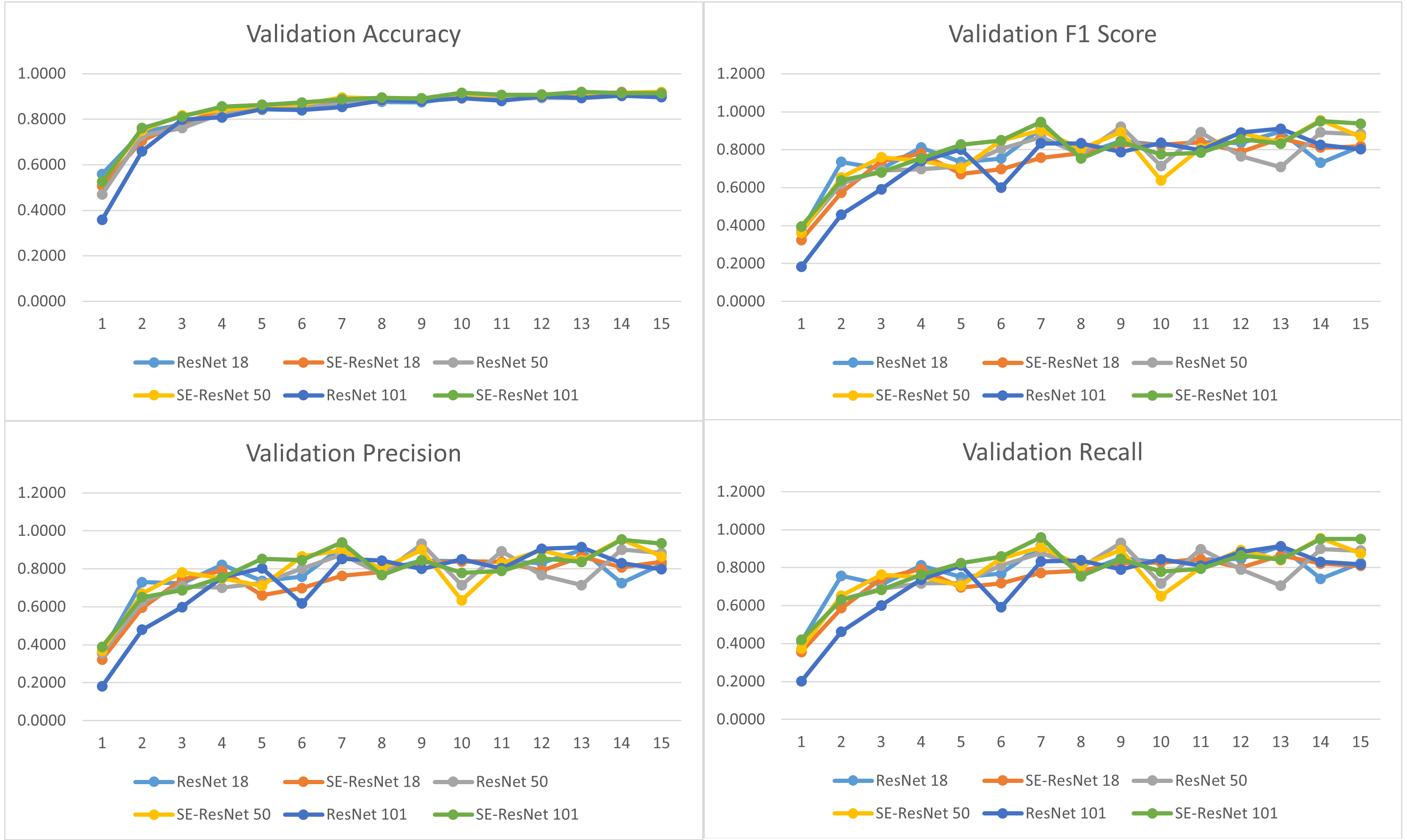
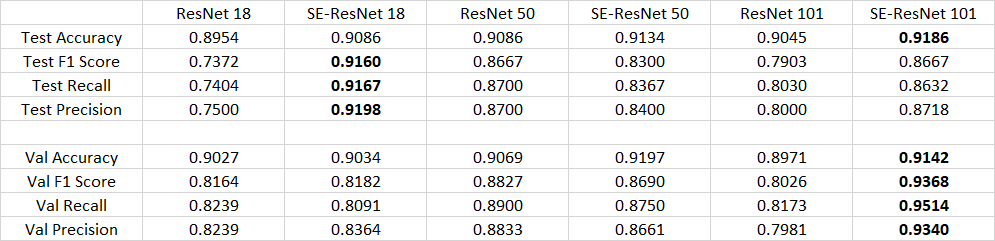
In the future, we can try to fine tune the hyper parameters and did error analysis to further understand the reasons why smaller model achieved better results. In addition, smaller models with better attention mechanism might indeed be able to achieve the same performance as deeper models. Hence, the seek for better attention mechanism besides squeeze and excitation network was also worth exploring. Furthermore, an early stopping technique could also be implemented to prevent overfitting. Currently, all 6 models finished training after a total of 15 epochs, which could be to many for a small dataset and resulted in overfitting. To prevent this, we can implement an early stoping technique. For example, if the f1 score decreased consecutively for 3 epochs, we might be able to assume that the model started to overfit, and thus we should terminate the training earlier.
References
Azizov, Said. "Road Sign Recognition." Kaggle. Retrieved June 13, 2021 from https://www.kaggle.com/michaelcripman/road-sign-recognition.
He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Krizhevsky, et al. "ImageNet Classification with Deep Convolutional Neural Networks." 2012.
Author
| Name | |
|---|---|
| Taiwei Shi | maksimstw@gatech.edu |
| Yitong Li | yli3277@gatech.edu |
| Ruikang Li | rakanli@gatech.edu |
| Xi Lin | xlin315@gatech.edu |
| Kelin Yu | kyu85@gatech.edu |